Vector Node to Graph Generation Data Flow
Overview
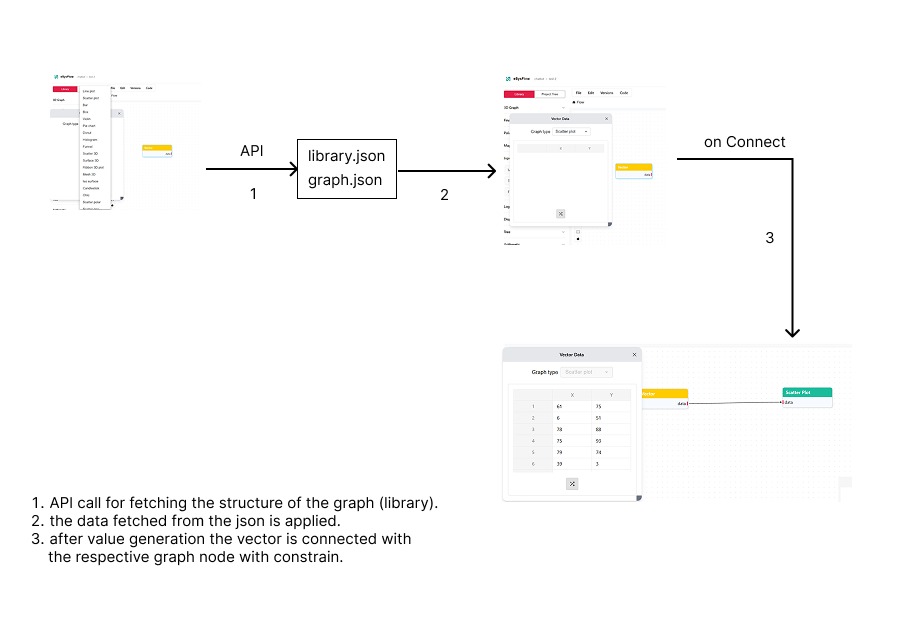
This document describes the complete data flow architecture in EsysFlow from vector node selection to graph visualization. The system implements a modular design where data flows through multiple components, APIs, and processing layers to generate interactive visualizations on the canvas.
Library Initialization and Component Loading
Application Bootstrap Process
Upon application initialization, the system performs library data fetching through the sidebar component. This process loads all available node definitions and categorizes them for efficient access and rendering.
Node Library Structure
The component library is organized into hierarchical categories: - Data Sources: Input nodes including Vector components for data ingestion - Arithmetic Operations: Mathematical computation nodes for data transformation - Visualization Components: Comprehensive chart types including: - Line plots for temporal data representation - Bar charts for categorical data comparison - Pie charts for proportional data visualization - 3D rendering components for multi-dimensional data - Financial Visualization: Specialized charts for financial data analysis - Geospatial Components: Map-based visualization tools for geographic data
Component Registration System
The system maintains a registry of available components, categorizing them by functionality and ensuring efficient retrieval during node instantiation. This architecture enables dynamic component loading and supports extensibility for future node types.
Vector Node Selection and Drag Operation
Component Discovery
The Vector node is located within the Data Sources category of the component library. This node serves as a data container component capable of handling various data formats and structures.
Drag-and-Drop Implementation
The system implements a drag-and-drop interface that supports component instantiation through direct manipulation. The drag operation captures component metadata including type identifiers and configuration parameters.
Event Handling Architecture
During the drag operation, the system: - Captures component type and metadata information - Prepares instantiation parameters for the target component - Maintains state information for proper component placement and initialization
Canvas Integration and Node Instantiation
Drop Event Processing
The canvas component processes drop events through a validation system that ensures proper placement within designated drop zones. This process includes coordinate transformation and boundary validation.
Node Creation Pipeline
Upon successful drop validation, the system executes: - Unique identifier generation for the new node instance - Position calculation and coordinate mapping within the canvas space - Component initialization with default configuration parameters - Registration within the React Flow state management system
State Management Integration
The instantiated Vector node becomes part of the canvas node collection, enabling it to participate in the broader data flow architecture. The system maintains references for efficient data access and component lifecycle management.
Vector Node Configuration and Data Management
Data Type Classification System
The Vector node supports multiple data format classifications: - Temporal Data: Time-series datasets with timestamp-value pairs for chronological analysis - Coordinate Data: X-Y coordinate pairs for scatter plot and correlation analysis - Categorical Data: Label-value associations for categorical visualization - Multi-dimensional Data: X-Y-Z coordinate sets for three-dimensional visualization
Data Input Architecture
The system provides multiple data ingestion methods: - Manual Input Interface: Direct data entry through form-based input components - Synthetic Data Generation: Programmatic data generation for testing and demonstration purposes
Data Validation Framework
The system implements comprehensive data validation including: - Format Consistency Validation: Ensures array length matching across dimensions - Type Validation: Verifies numeric and string data type consistency - Range Validation: Performs boundary checking for reasonable value ranges - Structure Validation: Confirms proper array formatting and data integrity
Internal Data Storage Model
The Vector node maintains structured data storage: - X-axis Data: Primary dimensional data for horizontal axis representation - Y-axis Data: Secondary dimensional data for vertical axis representation - Z-axis Data: Tertiary dimensional data for three-dimensional visualization support - Label Data: Categorical identifiers and metadata - Configuration Metadata: Type information, formatting preferences, and display options
Visualization Component Selection and Deployment
Chart Type Classification
The visualization library provides comprehensive chart types optimized for specific data patterns: - Line Charts: Temporal data visualization for trend analysis and time-series representation - Bar Charts: Categorical data comparison with discrete value representation - Pie Charts: Proportional data visualization for part-to-whole relationships - Scatter Plots: Correlation analysis and relationship identification between variables - 3D Visualizations: Multi-dimensional data representation with spatial depth - Financial Charts: Specialized visualizations for financial data analysis including candlestick and OHLC formats
Component Instantiation Process
Chart component deployment follows the established drag-and-drop pattern, utilizing the same instantiation pipeline as Vector nodes. The system maintains consistency in component creation and canvas integration across all node types.
Data Flow Connection Architecture
Connection Interface Implementation
The system implements a handle-based connection interface utilizing output ports on source nodes and input ports on target nodes. This design pattern enables visual data flow representation and maintains clear data lineage.
Edge Creation Protocol
Connection establishment follows a defined protocol: 1. Output handle activation on the Vector node initiates connection mode 2. Input handle targeting on the visualization component validates connection compatibility 3. Edge creation establishes persistent data flow relationship between components
Data Relationship Management
Established connections create: - Source Reference Mapping: Direct node-to-node relationship identification - Automatic Data Propagation: Real-time updates from source to target components - Connection Persistence: State maintenance across application sessions - Metadata Storage: Connection type and mapping information retention
Visualization Rendering and Interactive Features
Data Processing Pipeline
Upon connection establishment, the visualization system executes: - Data Extraction: Retrieval of structured data from connected Vector nodes - Format Transformation: Conversion of internal data structures to visualization library requirements - Configuration Integration: Merging of data with chart-specific styling and configuration parameters - Rendering Execution: Generation of interactive visualization components
Interactive Visualization Capabilities
The system provides comprehensive interactive features through Plotly.js integration: - Zoom Operations: Dynamic scaling for detailed data examination - Pan Functionality: Navigation across large datasets with smooth transitions - Hover Information: Contextual data point details and metadata display - Performance Optimization: Efficient rendering algorithms for large dataset handling
System Architecture Summary
Data Flow Pipeline
The complete data flow process encompasses nine distinct phases: 1. Library Initialization → Component library loading and categorization 2. Vector Node Selection → Data source component identification and selection 3. Component Instantiation → Canvas-based node creation and positioning 4. Data Configuration → Data input, validation, and storage processes 5. Visualization Selection → Chart type selection and component instantiation 6. Connection Establishment → Data flow relationship creation between components 7. Rendering Pipeline → Data processing and visualization generation 8. Interactive Integration → User interaction capabilities and real-time updates 9. State Persistence → Application state management and data persistence
Core Architecture Principles
The system architecture is built on several foundational principles: - Modular Component Design: Discrete, reusable components with defined interfaces - Visual Data Flow Paradigm: Intuitive drag-and-drop interface with visual connection representation - Real-time Data Propagation: Automatic updates across connected components - Extensible Framework: Support for additional node types and visualization components - Persistent State Management: Comprehensive state preservation across application sessions
Technical Implementation Components
The system implementation utilizes the following core modules:
- Sidebar Component: src/modules/canvas/widgets/sidebar/component/sidebar.tsx
- Canvas Engine: src/modules/canvas/components/canvas.tsx
- Vector Node Implementation: src/components/nodes/VectorNode.tsx
- Visualization Components: src/components/nodes/[GraphType]Node.tsx
- Flow Management Utilities: src/modules/canvas/widgets/spreadsheet/hooks/flowUtils.ts
- Library API Service: src/app/api/library/route.ts
- Component Library Data: public/data/library/graph.json
- Persistence API: src/app/api/saveFlowData/route.ts